Writing custom TypeScript ESLint rules: How I learned to love the AST
Posted on November 23, 2020
In this blog post, we’re going to learn how to write a custom ESLint plugin to help you with otherwise manual tasks that would take you days.
 The task? An eslint rule that adds generic to enzyme shallow calls, so we avoid type errors about our components during tests.
The task? An eslint rule that adds generic to enzyme shallow calls, so we avoid type errors about our components during tests.
Let’s dive into the world of ASTs: They’re not as scary as they seem!
Why writing your own eslint plugins and rules ?
- It’s fun to write and helps you learn more about JS/TS
- It can help enforce company-specific styles and patterns
- It can save you days of work 😃
There are already plenty of rules out there, ranging from how to style your curly braces, to not returning an await expression from async functions or even not initializing variables with undefined.
The thing is, lint rules are virtually infinite. In fact, we regularly see new plugins popping up for certain libraries, frameworks or use cases. So why not write yours? It’s not so scary, I promise!
The (not so) imaginary problem we’re solving
Tutorials often use foo,bar and baz or similar abstract notions to teach you something. Why not solve a real problem instead? A problem we encountered in a team while trying to solve some TypeScript type errors after the conversion to TypeScript.
If you’ve used enzyme to test a TypeScript React codebase, you probably know that shallow calls accept a generic, your component. e.g shallow<User>(<User {...props}).
 enzyme’s shallow type definition from DefinitelyTyped
enzyme’s shallow type definition from DefinitelyTyped
What if you don’t pass it? It might be “fine”, but as soon as you’ll try to access a component’s props or methods, you’ll have type errors because TypeScript thinks your component is a generic react component, with no props, state, or methods.
Of course if you’re writing new tests from scratch, you’d catch it instantly with your IDE or TypeScript tsc command and add the generic. But you might need to add it in 1, 100, or even 1000 tests, for instance because:
- You migrated a whole project from JS to TS, with no typings at all
- You migrated a whole project from flow to TS, with missing typings for some libraries
- You’re a new contributor to a TS project using enzyme to test react components, and aren’t familiar with generics
In fact, that’s a problem I’ve experienced in a team, and the same eslint rule we’ll write today saved us a lot of time by fixing this in our whole project.
How does ESLint work? The magic of ASTs
Before we start digging into creating ESLint rules, we need to understand what are ASTs and why they’re so useful to use as developers.
ASTs, or Abstract Syntax Trees, are representations of your code as a tree that the computer can read and manipulate.
We write code for computers in high-level, human-understandable languages like C, Java, JavaScript, Elixir, Python, Rust… but the computer is not a human: in other words, it has no way of knowing the meaning of what we write. We need a way for the computer to parse your code from a syntactical standpoint, to understand that const is a variable declaration, {} marks the beginning of an object expression sometimes, of a function in others… etc. This is done through ASTs, a needed step.
Once it understands it, we can do many things with it: execute it by passing it to an engine, lint it... or even generate new code by doing the same process the other way around.
To quote Jason Williams, a basic architecture for generating ASTs can be:
We break down our code into various tokens with semantic meaning (a.k.a lexical analyzer/tokenizer), group them and send them as groups of characters to a parser that will generate expressions, that can hold other expressions. -- Jason Williams - Let’s build a JavaScript Engine in Rust @ JSConf EU 2019
Such tree sounds familiar? This is very similar to the way your HTML code will be parsed into a tree of DOM nodes. In fact, we can generate abstract representations of any language as long as there’s a parser for it.
Let’s take a simple JS example:
const user = {
id: 'unique-id-1',
name: 'Alex',
}It can be represented like this with an AST:
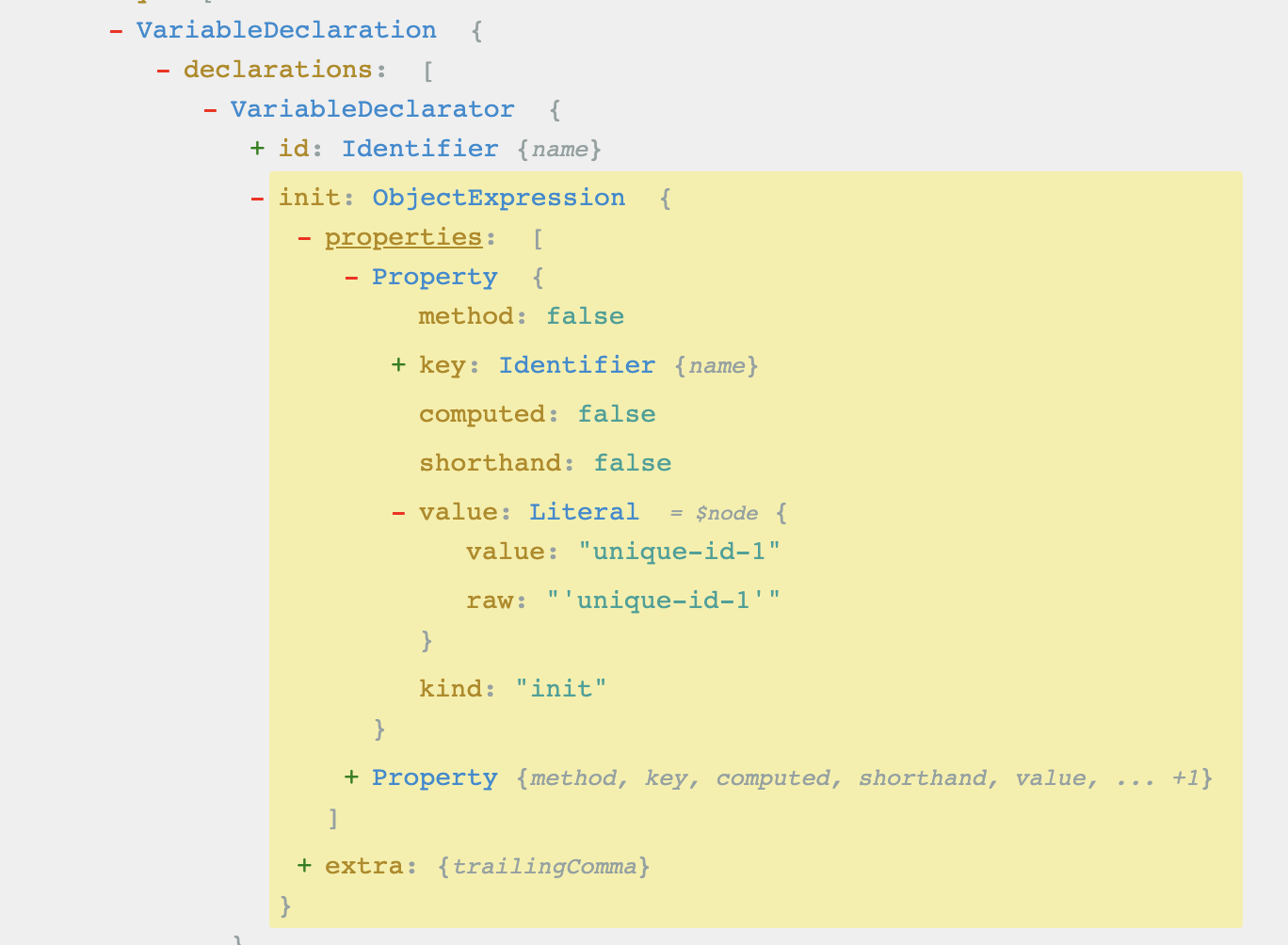 Abstract representation of our JS code in AST Explorer
Abstract representation of our JS code in AST Explorer
To visualize it, we use one excellent tool: https://astexplorer.net. It allows us to visualize syntax trees for many languages. I recommend pasting different bits of JS and TS code there and exploring the tool a little bit, as we will use it later!
Make sure to select the language of the code you’re pasting to get the right AST for it!
Creating a TS project to lint
If you already have a TS + React + Jest project, feel free to skip to the next section, or pick just what you need from this one!
Let’s create a dummy React + TypeScript + Jest + Enzyme project, that will suffer from the typing issue we’ve seen earlier.
Conceptually, parsing TypeScript code is no different than JS code, we need a way to to parse the TS code into a tree. Thankfully, the typescript-eslint plugin already ships with its own TS parser. So let’s start!
Create an ast-learning folder and add a package.json file containing react, jest, enzyme, eslint, and all type definitions.
{
"name": "ast-learning",
"version": "1.0.0",
"description": "Learn ASTs by writing your first ESLint plugin",
"main": "src/index.js",
"dependencies": {
"react": "17.0.0",
"react-dom": "17.0.0",
"react-scripts": "3.4.3"
},
"devDependencies": {
"[@babel/preset-env](http://twitter.com/babel/preset-env)": "^7.12.1",
"[@babel/preset-react](http://twitter.com/babel/preset-react)": "^7.12.5",
"[@types/enzyme](http://twitter.com/types/enzyme)": "^3.10.8",
"[@types/enzyme-adapter-react-16](http://twitter.com/types/enzyme-adapter-react-16)": "^1.0.6",
"[@types/jest](http://twitter.com/types/jest)": "^26.0.15",
"[@types/react](http://twitter.com/types/react)": "^16.9.56",
"[@types/react-dom](http://twitter.com/types/react-dom)": "^16.9.9",
"[@typescript](http://twitter.com/typescript)-eslint/eslint-plugin": "^4.8.1",
"[@typescript](http://twitter.com/typescript)-eslint/parser": "^4.8.1",
"babel-jest": "^26.6.3",
"enzyme": "3.11.0",
"enzyme-adapter-react-16": "1.15.5",
"eslint": "^7.13.0",
"jest": "^26.6.3",
"react-test-renderer": "^17.0.1",
"ts-jest": "^26.4.4",
"typescript": "3.8.3"
},
"scripts": {
"lint": "eslint ./*.tsx",
"test": "jest index.test.tsx",
"tsc": "tsc index.tsx index.test.tsx --noEmit true --jsx react"
}
}Let’s also create a minimal tsconfig.json file to make TypeScript compiler happy :).
{
"compilerOptions": {
"allowSyntheticDefaultImports": true,
"module": "esnext",
"lib": ["es6", "dom"],
"jsx": "react",
"moduleResolution": "node"
},
"exclude": [
"node_modules"
]
}As a last configuration step to our project, let’s add .eslintrc.js with empty rules for now:
export default {
"parser": "[@typescript](http://twitter.com/typescript)-eslint/parser",
"parserOptions": {
"ecmaVersion": 12,
"sourceType": "module"
},
"plugins": [
"[@typescript](http://twitter.com/typescript)-eslint",
"ast-learning",
],
"rules": {
}
}Now that our project has all the config ready, let’s create our index.tsx containing a User component:
import * as React from "react";
type Props = {};
type State = { active: boolean };
class User extends React.Component<Props, State> {
constructor(props: Props) {
super(props);
this.state = { active: false };
}
toggleIsActive() {
const { active } = this.state;
this.setState({ active: !active });
}
render() {
const { active } = this.state;
return (
<div className="user" onClick={() => this.toggleIsActive()}>
User is {active ? "active" : "inactive"}
</div>
);
}
}
export {User}And a test file called index.test.tsx:
import * as React from 'react'
import * as Adapter from "enzyme-adapter-react-16";
import * as enzyme from "enzyme";
import {User} from './index'
const {configure, shallow} = enzyme
configure({ adapter: new Adapter() });
describe("User component", () => {
it("should change state field on toggleIsActive call", () => {
const wrapper = shallow(<User />);
// @ts-ignore
wrapper.instance().toggleIsActive();
// @ts-ignore
expect(wrapper.instance().state.active).toEqual(true);
});
it("should change state field on div click", () => {
const wrapper = shallow(<User />);
wrapper.find(".user").simulate("click");
// @ts-ignore
expect(wrapper.instance().state.active).toEqual(true);
});
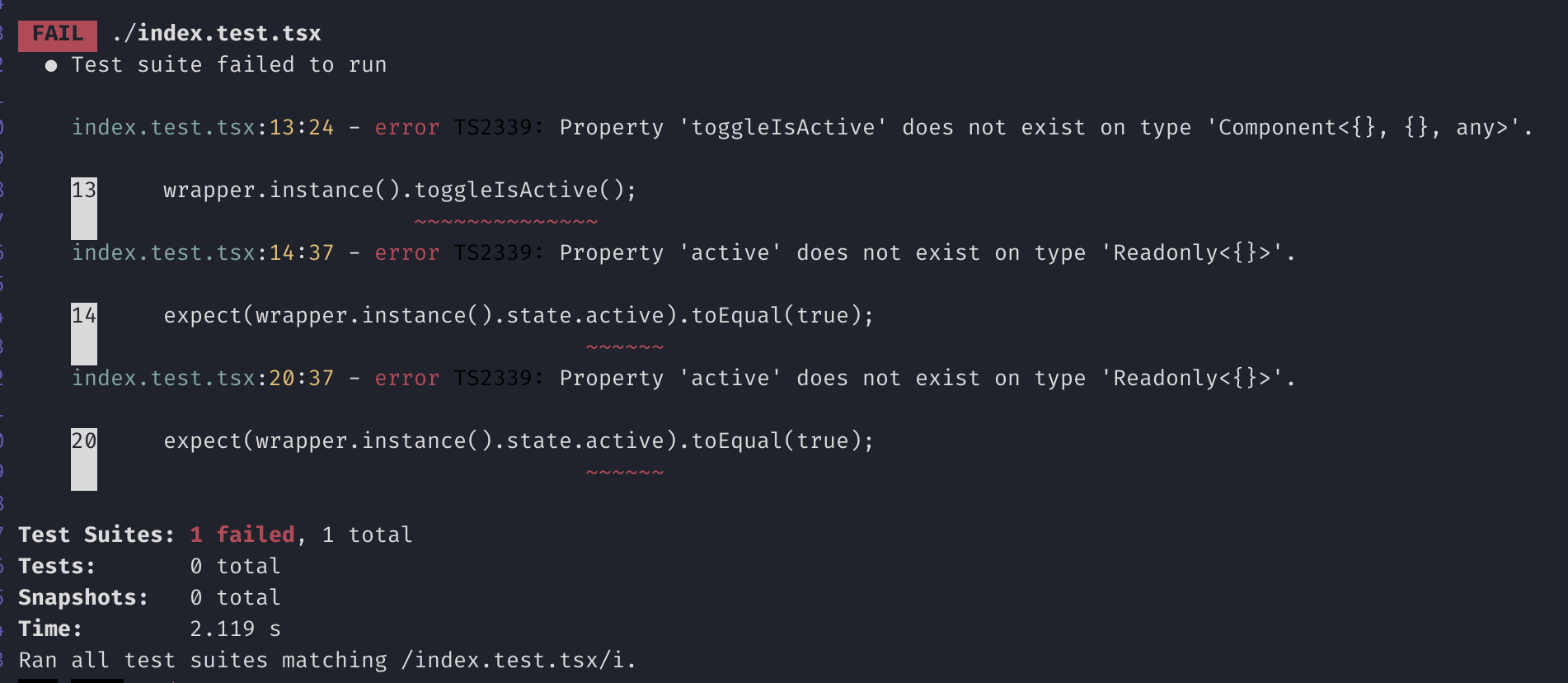
});Now run npm i && npx ts-jest config:init && npm run test. We can see that the TSX compiles fine due to the // @ts-ignore directive comments.
@ts-ignore directive comments instruct the TypeScript compiler to ignore the type errors on the next line. So, it compiles and tests run fine, all is good?Nope! Let’s remove the @ts-ignore directive comments and see what happens.
❌❌ Now the tests don’t even run, and we have 3 TypeScript errors in our tests.
Oh no 😞! As seen in the intro, we could fix it by adding the generic to all our shallow calls manually. Could, but probably shouldn’t.
const wrapper = shallow<User>(<User />); // here, added User generic typeThe pattern is very simple here, we need to get the argument that shallow is called with, then pass it as a type argument (a.k.a generic).
Surely we can have the computer generate this for us? If there is a pattern, there is automation.
Yay, that’s our use-case for a lint rule! Let’s write code that will fix our code for us 🤯
If there’s a pattern, there’s automation
If you can find patterns in your code that could be done by your computer to analyze, warn you, block you from doing certain things, or even write code for you, there’s magic to be done with AST. In such cases, you can:
-
Write an ESLint rule, either:
- with autofix, to prevent errors and help with conventions, with auto- generated code
- without autofix, to hint developer of what he should do
- Write a codemod. A different concept, also achieved thanks to ASTs, but made to be ran across big batches of file, and with even more control over traversing and manipulating ASTs. Running them across your codebase is an heavier operation, not to be ran on each keystroke as with eslint.
As you’ve guessed, we’ll write an eslint rule/plugin. Let’s start!
Initializing our eslint plugin project
Now that we have a project to write a rule for, let’s initialize our eslint plugin by creating another project folder called eslint-plugin-ast-learning next to ast-learning
⚠️ ️eslint plugins follow the convention
eslint-plugin-your-plugin-name!
Let’s start by creating a package.json file:
{
"name": "eslint-plugin-ast-learning",
"description": "Our first ESLint plugin",
"version": "1.0.0",
"main": "index.js"
}And an index.js containing all of our plugin’s rules, in our case just one, require-enzyme-generic:
const rules = {
'require-enzyme-generic': {
meta: {
fixable: 'code',
type: 'problem',
},
create: function (context) {
return {
}
},
},
}
module.exports = {
rules,
}Each rule contain two properties: meta and create.You can read the documentation here but the tl;dr is that
- the
metaobject will contain all informations about your rule to be used by eslint, for example: - In a few words, what does it do?
- Is it autofixable?
- Does it cause errors and is high priority to solve, or is it just stylistic
- What’s the link of the full docs?
- the
createfunction will contain the logic of your rule. It’s called with a context object, that contains many useful properties documented here.
It returns an object where keys can be any of the tokens that exist in the AST you’re currently parsing. For each of these tokens, eslint will let you write a method declaration with the logic for this specific token. Example of tokens include:
-
CallExpression: a function call expression, e.g:
shallow() -
VariableDeclaration: a variable declaration (without the preceding var/let/const keyword) e.g:
SomeComponent = () => (<div>Hey there</div>) - StringLiteral: a string literal e.g
'test'
The best way to understand what’s what, is to paste your code in ASTExplorer (while making sure to select the right parser for your language) and explore the different tokens.
Defining the criteria for the lint error to kick in
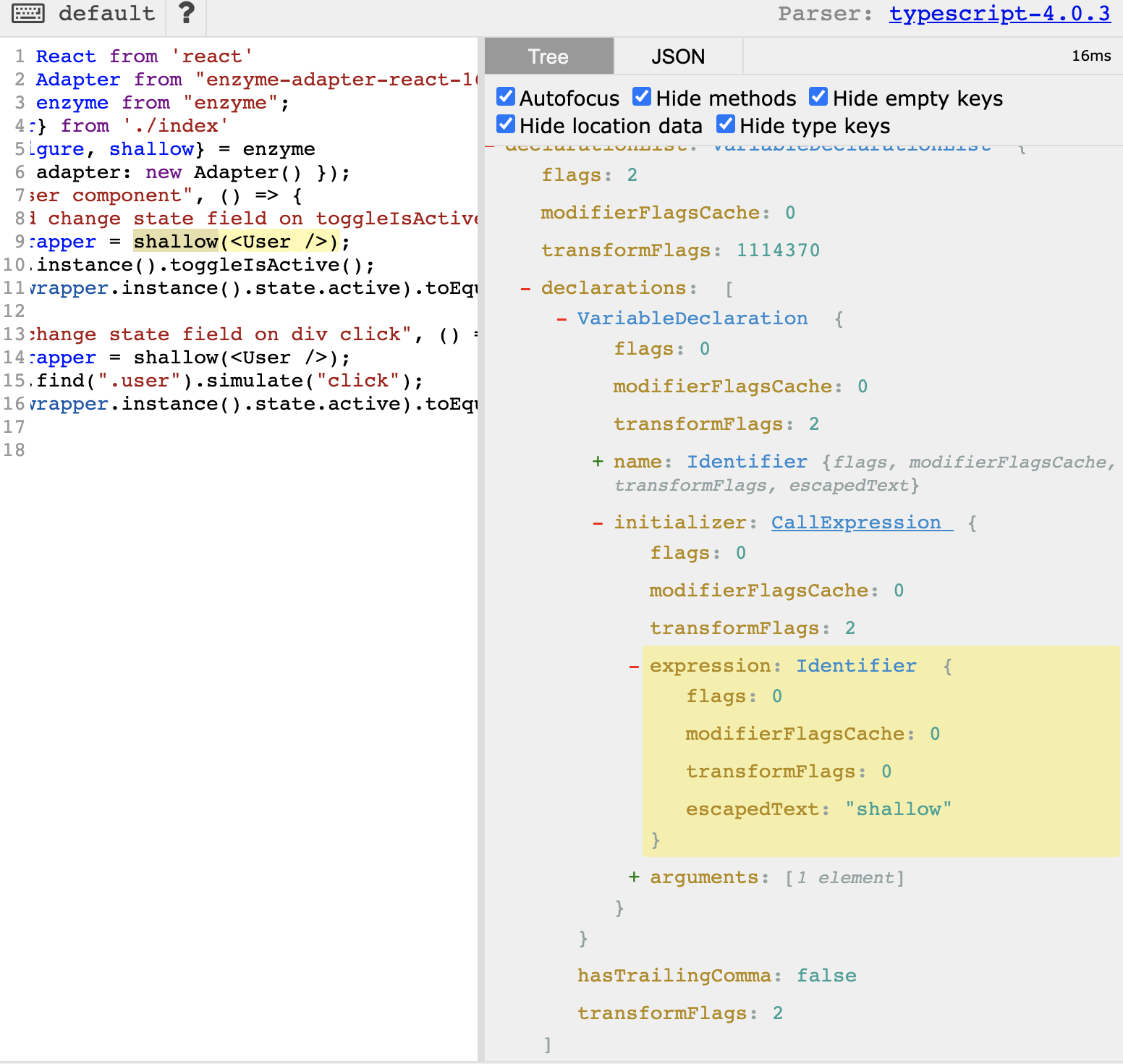 ASTExplorer output for our code
ASTExplorer output for our code
Go to the left pane of AST explorer and select our shallow() call (or hover over the corresponding property on the right pane): you’ll see that it is of type CallExpression
So let’s add the CallExpression property to the object returned by our create method:
create: function (context) {
return {
CallExpression (node) {
// TODO: Magic 🎉
}
}
}Each method that you will declare will be called back by ESLint with the corresponding node when encountered.
If we look at babel (the AST format that the TS parser uses) docs, we can see that the node for CallExpression contains a callee property, which is an Expression. An Expression has a name property, so let’s create a check inside our CallExpression method
CallExpression (node) {
if ((node.callee.name === 'shallow')) // run lint logic on shallow calls
}We also want to make sure that we only target the shallow calls without a generic already there. Back to AST Explorer, we can see there is an entry called typeArguments, which babel AST calls typeParameters, which is an array containing the type argument(s) of our function call. So let’s make sure it’s undefined (no generic e.g shallow() or empty generic e.g shallow<>) or is an empty array (meaning we have a generic with nothing inside).
if (
node.callee.name === 'shallow' &&
!node.typeParameters
)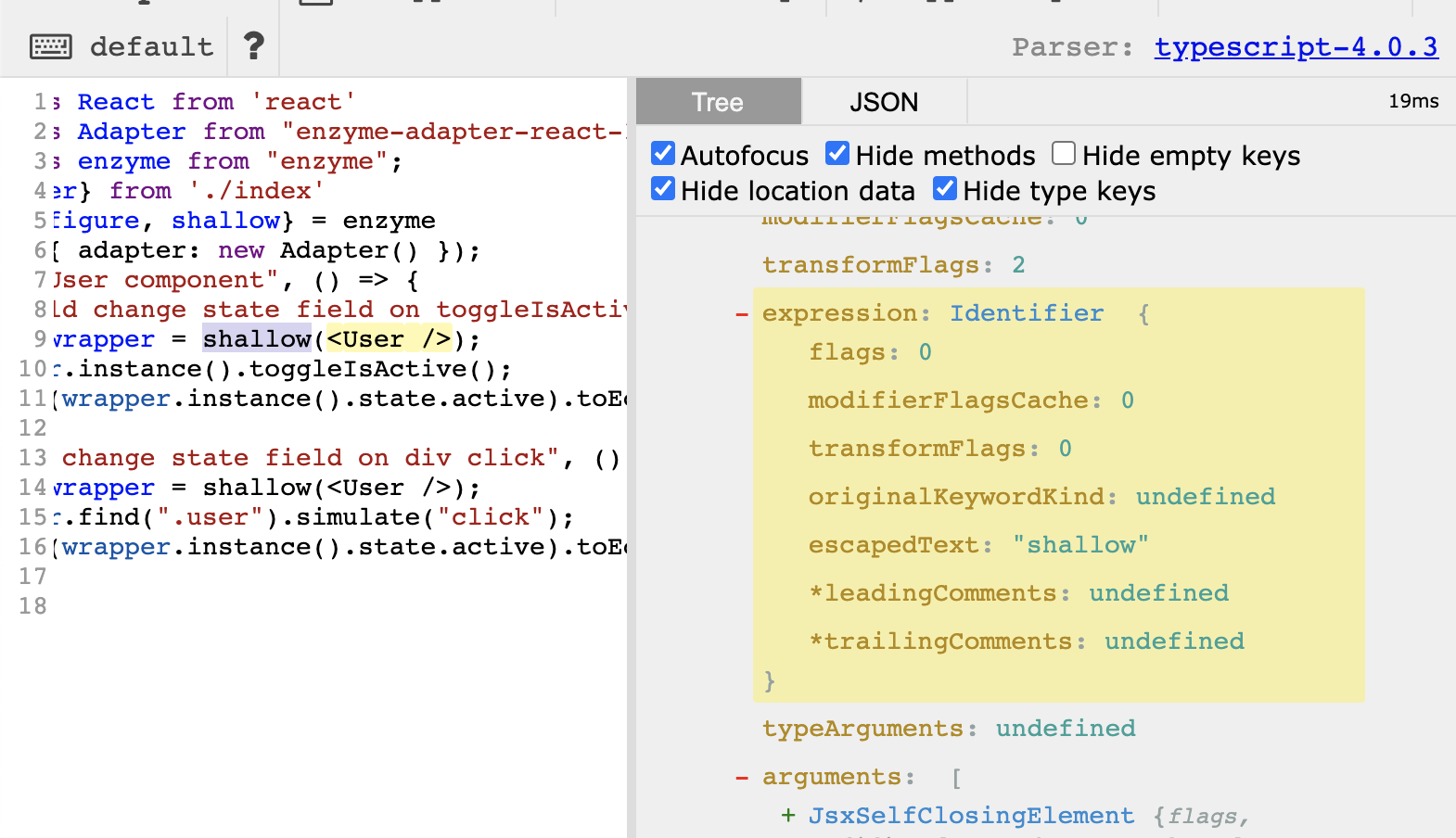
Here we go! We found the condition in which we should report an error.
The next step is now to use context.report method. Looking at the ESLint docs, we can see that this method is used to report a warning/error, as well as providing an autofix method:
The main method you’ll use is
context.report(), which publishes a warning or error (depending on the configuration being used). This method accepts a single argument, which is an object containing the following properties: (Read more in ESLint docs)
We will output 3 properties:
node(the current node). It serves two purposes: telling eslint where the error happened so the user sees the line info when running eslint / highlighted in his IDE with eslint plugin. But also what is the node so we can manipulate it or insert text before/aftermessage: The message that will be reported by eslint for this error-
fix: The method for autofixing this nodeCallExpression (node) { if ( node.callee.name === 'shallow' && !(node.typeParameters && node.typeParameters.length) ) { context.report({ node: node.callee, // shallow message: `enzyme.${node.callee.name} calls should be preceded by their component as generic. ` + "If this doesn't remove type errors, you can replace it with <any>, or any custom type.", fix: function (fixer) { // TODO }, }) } }
We managed to output an error. But we would like to go one step further and fix the code automatically, either with `eslint --fix` flag, or with our IDE eslint plugin.
Let’s write that fix method!
## Writing the `fix` method
First, let’s write an early return that will insert `<any>` after our shallow keyword in case we’re not calling shallow() with some JSX Element.
To insert after a node or token, we use the `insertTextAfter` method.
> insertTextAfter(nodeOrToken, text) - inserts text after the given node or token
```js
const hasJsxArgument = node.arguments && node.arguments.find((argument, i) => i === 0 && argument.type === 'JSXElement')
if (!hasJsxArgument) {fixer.insertTextAfter(node.callee, '<any>')}After that early return, we know that we have a JSX Element as first argument. If this is the first argument (and it should, shallow() only accepts a JSXElement as first argument as we’ve seen in its typings), let’s grab it and insert it as generic.
const expressionName = node.arguments[0].openingElement.name.name
return fixer.insertTextAfter(node.callee, `<${expressionName}>`)That’s it! We’ve captured the name of the JSX expression shallow() is called with, and inserted it after the shallow keyword as a generic.
Let’s now use our rule in the project we’ve created before!
Using our custom plugin
Back to our ast-learning project, let’s install our eslint plugin npm package:
npm install ../eslint-plugin-ast-learningSo far if we lint our file that shouldn’t pass ling by running npm run lint, or open index.test.tsx with our editor if it has an eslint plugin installed, we’ll see no errors as we didn’t add the plugin and rule yet.
Let’s add them to our .eslintrc.js file:
module.exports = {
"parser": "[@typescript](http://twitter.com/typescript)-eslint/parser",
"parserOptions": {
"ecmaVersion": 12,
"sourceType": "module"
},
"plugins": [
"[@typescript](http://twitter.com/typescript)-eslint",
"ast-learning", // eslint-plugin-ast-learning
],
"rules": {
"ast-learning/require-enzyme-generic": 'error'
}
}If you run npm run lint again or go to the file with your IDE that has eslint plugin, you should now see errors:
/Users/alexandre.gomes/Sites/ast-learning/index.test.tsx
12:21 error enzyme.shallow calls should be preceeded by their component as generic. If this doesn't remove type errors, you can replace it
with <any>, or any custom type ast-learning/require-enzyme-generic
20:21 error enzyme.shallow calls should be preceeded by their component as generic. If this doesn't remove type errors, you can replace it
with <any>, or any custom type ast-learning/require-enzyme-generic
✖ 2 problems (2 errors, 0 warnings)
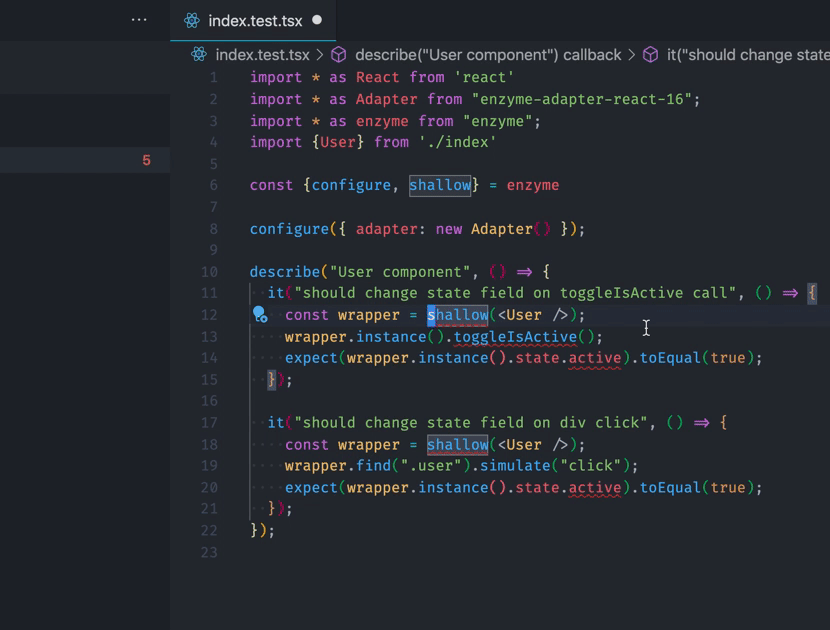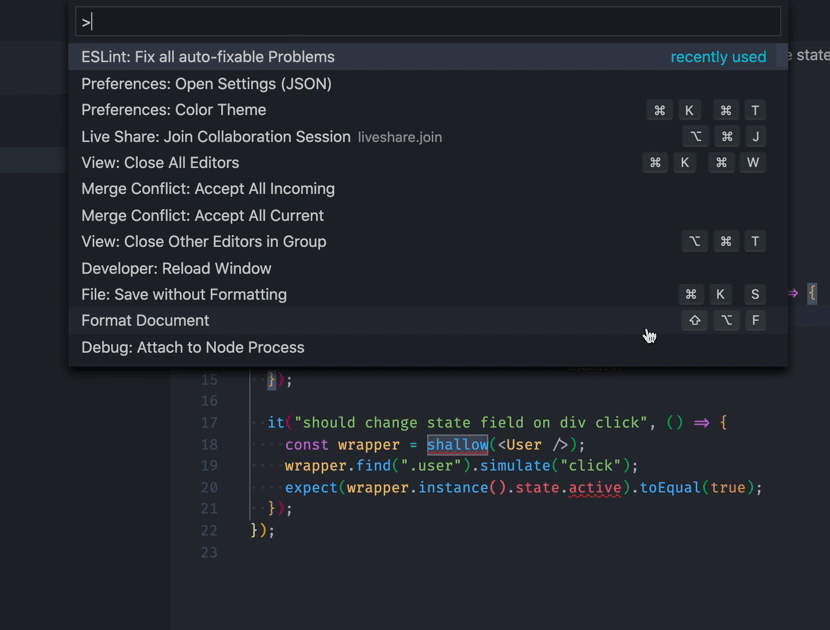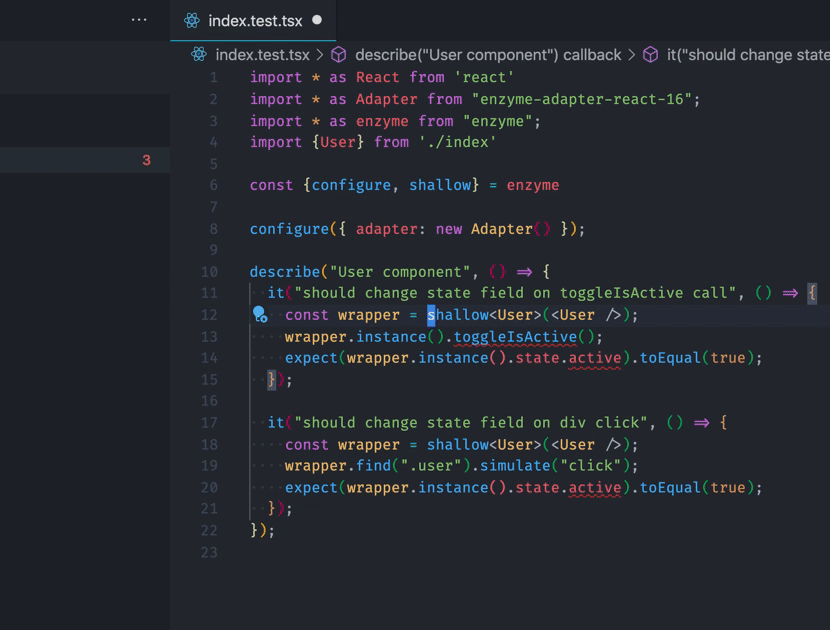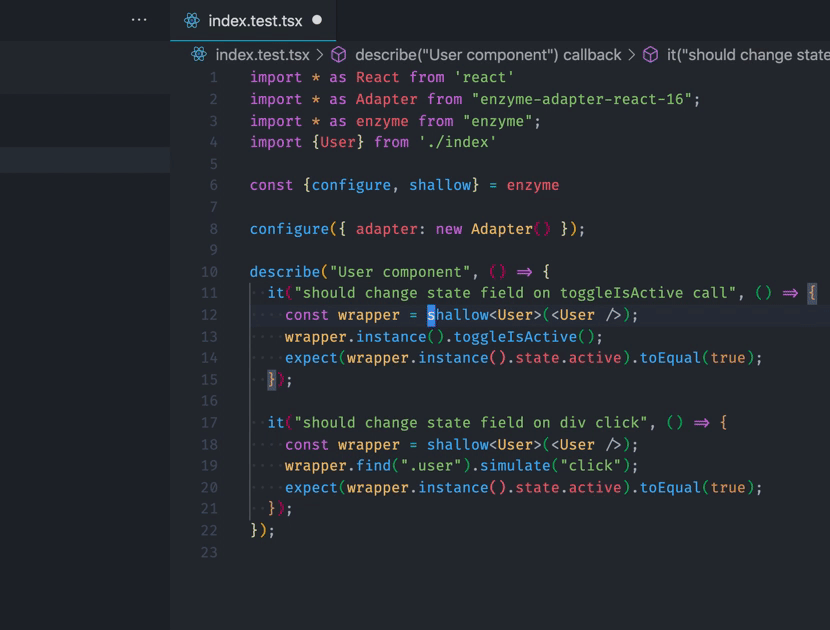
2 errors and 0 warnings potentially fixable with the `--fix` option.They can be fixed automatically, interesting! Why don’t we try?
❯ npm run lint -- --fix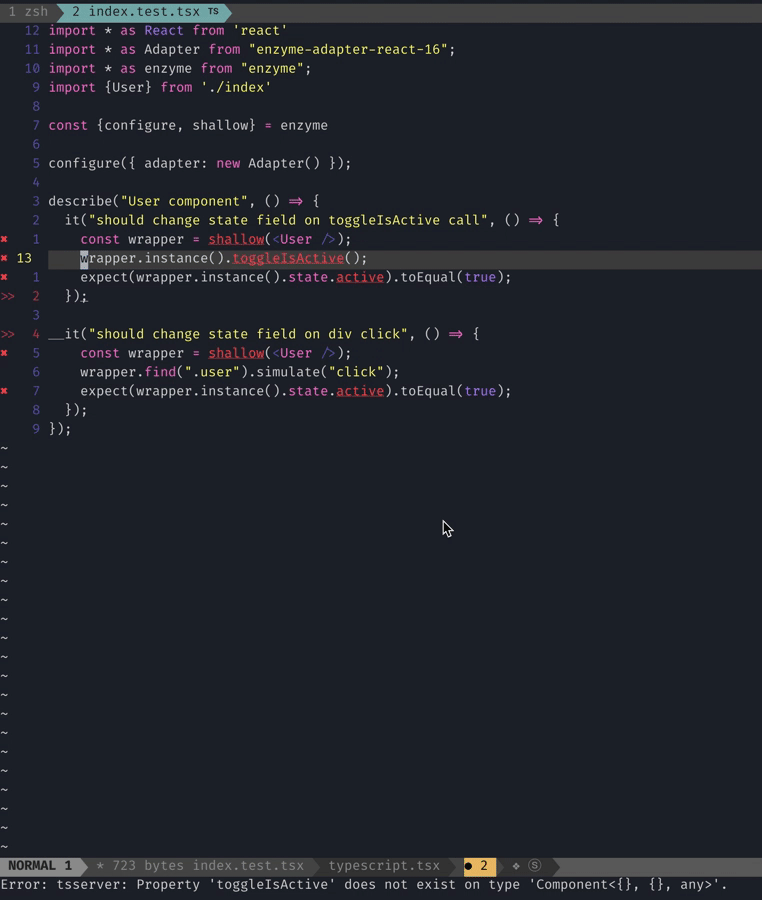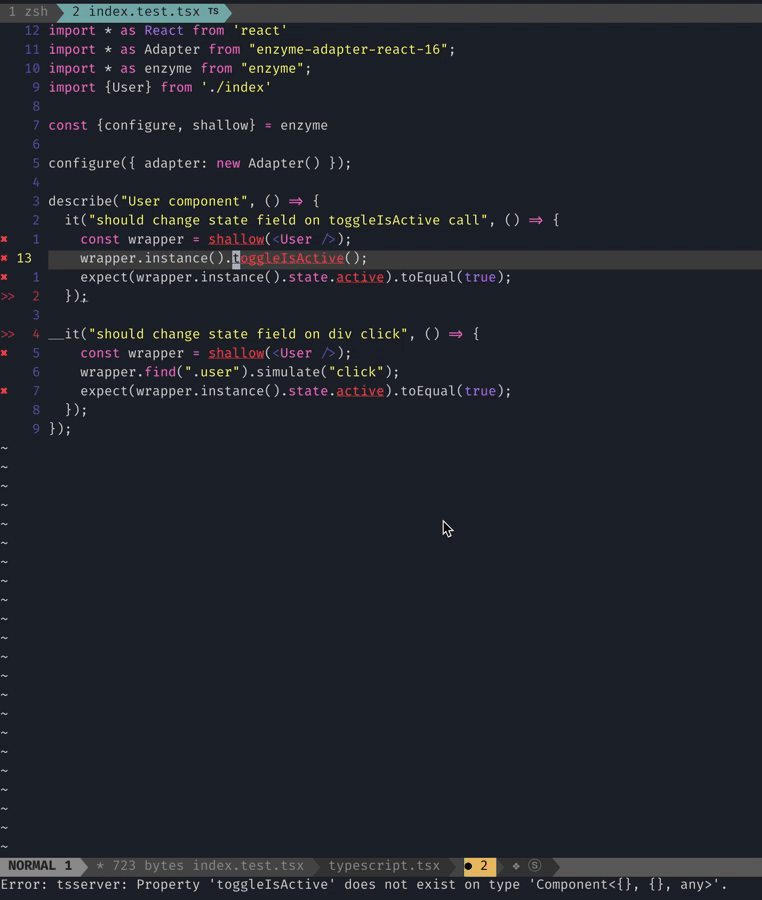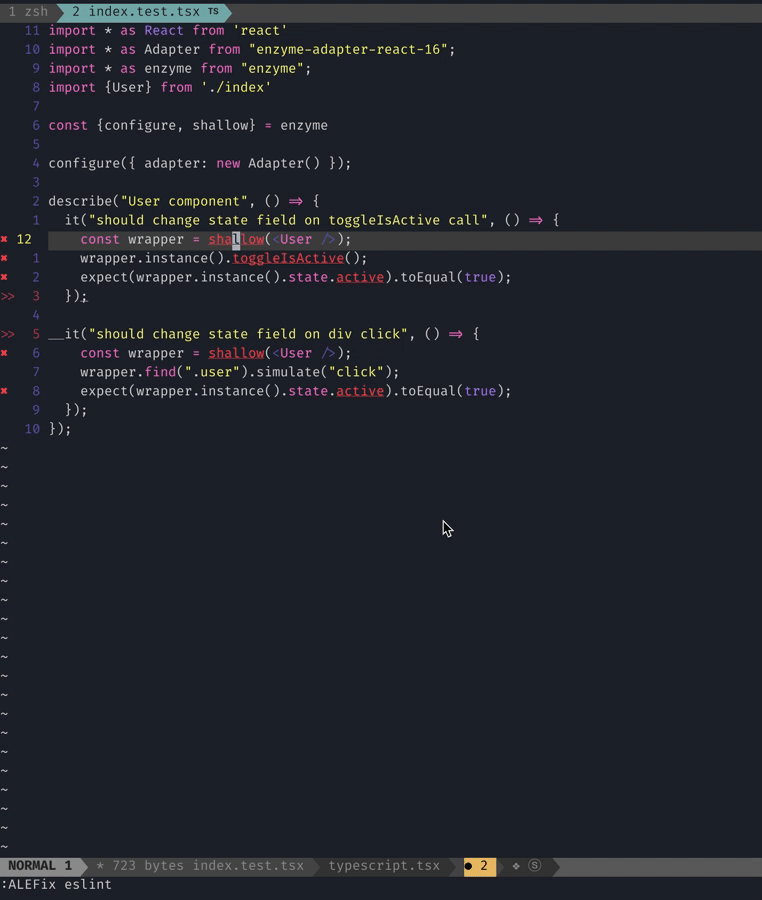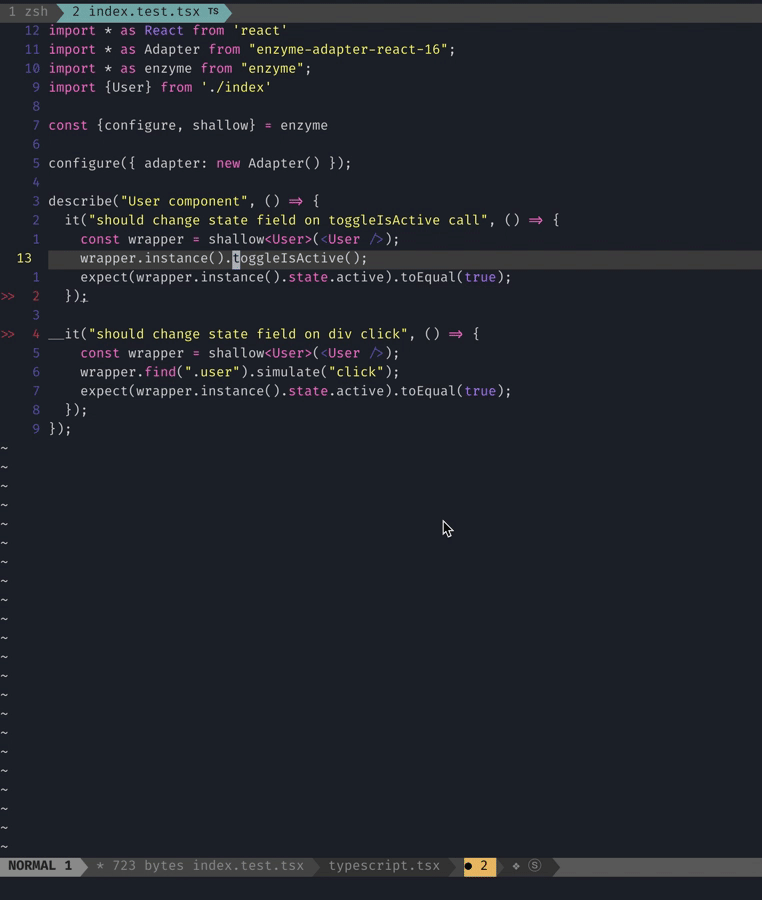
Woohoo! Our files now have the generic in them. Now imagine it running in 1000s of files. The power of code generation!
Going further
If you want to learn more about ESLint custom plugins, you’ll need to read through the ESLint docs that are very complete.
You’ll also want to add extensive tests for your rules, as from experience, eslint autofixes (and jscodeshift codemods, the topic of another post) have a lot of edge cases that could break your codebase. Not only are tests sine qua non to your rules being reliable, but also to contributing an official rule 😉